Datanormalisatie: de Derde Normaalvorm (3NF) is essentieel voor je database
Gerelateerde artikelen

Datanormalisatie
Als je begint met programmeren en databases, kom je al snel in aanraking met het organiseren van data. Een van de belangrijkste concepten hierbij is datanormalisatie. Dat is de meest logische manier om je data netjes en bruikbaar te houden. In dit artikel duiken we in de basis van datanormalisatie en leggen we uit waarom de Derde Normaalvorm (3NF) zo belangrijk is voor software ontwikkelaars.
Als we een applicatie bouwen die informatie moet opslaan – bijvoorbeeld over klanten en hun bestellingen – kunnen we alle informatie in één grote lijst opslaan. Al snel merken we dat dit leidt tot rommel, dubbele data en problemen bij het verwerken van informatie. Dit is het punt waar datanormalisatie om de hoek komt kijken.
Wat is Datanormalisatie?
Denk aan datanormalisatie als het organiseren van een chaotische archiefkast. In plaats van overal willekeurig documenten neer te leggen en belangrijke papieren meerdere keren te kopiëren (wat leidt tot verwarring als we iets bijwerken), organiseren we alles systematisch. We maken mappen voor verschillende soorten informatie en zorgen ervoor dat elk uniek stukje informatie maar op één logische plek wordt bewaard of duidelijk gelinkt is.
In de wereld van databases betekent datanormalisatie het organiseren van data in tabellen en kolommen om twee hoofddoelen te bereiken:
- Redundantie Verminderen: Voorkomen dat we dezelfde informatie onnodig meerdere keren opslaan. Dit bespaart opslagruimte en, belangrijker nog, maakt onze data gemakkelijker te managen.
- Data-integriteit Verbeteren: Zorgen dat onze data betrouwbaar, consistent en accuraat is. Minder redundantie betekent minder kans op inconsistenties.
De “Normaalvormen”: verschillende niveaus van organisatie
Datanormalisatie kent verschillende niveaus, ook wel normaalvormen genoemd (1NF, 2NF, 3NF, BCNF, etc.). Elke normaalvorm heeft strengere regels dan de vorige en helpt onze data verder te organiseren.
- Eerste Normaalvorm (1NF): De absolute basis. Zorgt ervoor dat elke “cel” in een tabel slechts één stukje data bevat en dat elke rij uniek te identificeren is (meestal met een primaire sleutel). Geen lijsten of herhalende groepen in één veld dus!
- Tweede Normaalvorm (2NF): Bouwt voort op 1NF. Als we een primaire sleutel hebben die uit meerdere kolommen bestaat (een samengestelde sleutel), dan moeten alle andere kolommen afhankelijk zijn van alle delen van die samengestelde sleutel, niet slechts een deel ervan.
Deze eerste twee vormen zijn belangrijk, maar het wordt pas echt krachtig als we kijken naar de derde normaalvorm.
Focus bij datanormalisatie op de Derde Normaalvorm (3NF): De Meest Voorkomende Standaard
De Derde Normaalvorm (3NF) is vaak het doel bij het ontwerpen van databases voor veel applicaties. Een tabel is in 3NF als deze:
- Al in de Tweede Normaalvorm (2NF) is.
- Geen transitieve afhankelijkheden heeft van niet-sleutelkolommen op de primaire sleutel.
“Transitieve afhankelijkheid” klinkt ingewikkeld, maar laten we het simpel maken.
Wat is een transitieve afhankelijkheid?
Het betekent dat een kolom C afhankelijk is van kolom B, die op zijn beurt afhankelijk is van kolom A (de primaire sleutel). Dus: A → B en B → C. Kolom C hangt via B af van A, maar is niet direct en volledig afhankelijk van A zelf.
Laten we dit illustreren met een voorbeeld:
Stel we hebt een tabel om bestellingen bij te houden, en we proberen hier ook klantgegevens in op te slaan:
Tabel: Bestellingen (Niet in 3NF)
| BestellingID (PK) | KlantID | KlantNaam | KlantStad | Product | Prijs |
| 101 | 1 | Jan Jansen | Amsterdam | Laptop | 800 |
| 102 | 2 | Piet Peeters | Utrecht | Muis | 20 |
| 103 | 1 | Jan Jansen | Amsterdam | Toetsen | 75 |
| 104 | 3 | Els Elshout | Eindhoven | Monitor | 300 |
In deze tabel is BestellingID de primaire sleutel (PK).
- KlantID, KlantNaam, KlantStad, Product, Prijs zijn allemaal afhankelijk van BestellingID.
- Maar kijk goed: KlantNaam en KlantStad zijn primair afhankelijk van KlantID, niet direct van BestellingID. De stad waar Jan Jansen woont (Amsterdam) hangt af van wie klant 1 is, niet van het feit dat hij bestelling 101 of 103 heeft geplaatst.
Hier zien we een transitieve afhankelijkheid: BestellingID → KlantID → KlantStad. De kolom KlantStad is transitief afhankelijk van de primaire sleutel via KlantID. Dit is een schending van 3NF.
Waarom is dit een probleem?
Deze transitieve afhankelijkheid leidt tot de problemen die we eerder noemden:
- Invoegingsprobleem: We kunnen een nieuwe klant niet toevoegen als die nog geen bestelling heeft geplaatst (we hebben een BestellingID nodig).
- Bijwerkingsprobleem: Als Jan Jansen verhuist naar Rotterdam, moeten we iedere rij bijwerken waar KlantID 1 voorkomt. Als we er één missen, is onze data inconsistent.
- Verwijderingsprobleem: Als we de laatste bestelling van Els Elshout (BestellingID 104) verwijderen, verliezen we ook de informatie dat Els Elshout (KlantID 3) in Eindhoven woont.
Hoe brengen we dit naar 3NF?
Om dit naar 3NF te brengen, verwijderen we de kolommen die transitief afhankelijk zijn (KlantNaam, KlantStad) en plaatsen we ze in een aparte tabel waar ze direct afhankelijk zijn van hun eigen primaire sleutel (KlantID).
We splitsen de tabel op in twee tabellen:
Tabel: Bestellingen (Nu in 3NF)
| BestellingID (PK) | KlantID (FK) | Product | Prijs |
| 101 | 1 | Laptop | 800 |
| 102 | 2 | Muis | 20 |
| 103 | 1 | Toetsen | 75 |
| 104 | 3 | Monitor | 300 |
Hier verwijst de kolom KlantID nu naar de Klanten tabel.
Tabel: Klanten (Nu in 3NF)
| KlantID (PK) | KlantNaam | KlantStad |
| 1 | Jan Jansen | Amsterdam |
| 2 | Piet Peeters | Utrecht |
| 3 | Els Elshout | Eindhoven |
Nu is in de Bestellingen tabel elke kolom (Product, Prijs, KlantID) direct afhankelijk van BestellingID. In de Klanten tabel zijn KlantNaam en KlantStad direct afhankelijk van KlantID. Er zijn geen transitieve afhankelijkheden meer ten opzichte van de primaire sleutel van de oorspronkelijke tabel.
Waarom is 3NF belangrijk en waarom zouden we ernaar streven?
Zoals te zien in het voorbeeld, lost het opsplitsen naar 3NF een aantal problemen op:
- Klantgegevens staan maar op één plek (Klanten tabel).
- Als een klant verhuist, werken we het adres maar op één plek bij (in de Klanten tabel).
- We kunnen een nieuwe klant toevoegen in de Klanten tabel, zelfs als deze nog geen bestelling heeft.
- We kunt een bestelling verwijderen zonder klantgegevens te verliezen.
Door onze database te normaliseren naar 3NF, creëren we een structuur die efficiënter omgaat met dataopslag en updates. Het vermindert het risico op inconsistenties aanzienlijk en maken onze database logischer en makkelijker te beheren en te bevragen. Voor de meeste standaard applicaties is 3NF een uitstekend niveau van normalisatie om naar te streven. Het biedt een goede balans tussen redundantie minimaliseren en de database bruikbaar houden.
Afwijken van 3NF (Denormalisatie)
Soms, in specifieke gevallen zoals bij datawarehouses of wanneer performance extreem kritiek is voor bepaalde queries, kiezen database-ontwerpers er bewust voor om af te wijken van 3NF. Dit heet denormalisatie. Hierbij wordt gecontroleerde redundantie teruggebracht in de database om joins te vermijden en zo leesoperaties te versnellen.
Het is belangrijk te onthouden dat denormalisatie een prestatie-optimalisatie is met een afweging: we maken leesoperaties sneller, maar schrijfoperaties complexer en introduceren het risico op inconsistentie. Daarom blijft 3NF het uitgangspunt en de best practice voor de meeste transactionele databases.
Bij denormalisatie is het overigens cruciaal om aanvullende technieken te gebruiken (zoals database triggers of zorgvuldige applicatielogica) om de inconsistenties te beheren, wat extra inspanning vereist.
Het data-model in een ERD Diagram
Als de applicatie en daardoor het aantal tabellen door datanormalisatie in omvang toenemen wordt het gebruik van een datamodel in een grafische weergave noodzakelijk. Anders verliezen we het overzicht en kunnen we moeilijk achterhalen in welke tabel een bepaald data-element is opgeslagen.
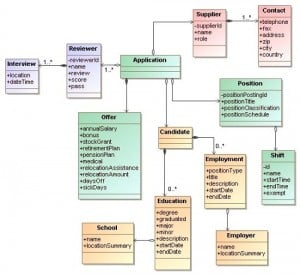
Datanormalisatie en het gebruik van een grafische weergave, zoals een Entity-Relationship Diagram (ERD), zijn daarom nauw met elkaar verbonden en worden steeds onmisbaarder naarmate een applicatie (en daarmee de database) complexer wordt.
We kunnen zeker stellen dat normalisatie het gebruik van een datamodel in een grafische weergave sterk aanmoedigt en praktisch noodzakelijk maakt, vooral bij grotere systemen.
Hier zijn een paar redenen waarom dit zo is:
- Datanormalisatie verdeelt data: Zoals we zagen bij 3NF, normalisatie houdt in dat we onze data opsplitsten in meerdere tabellen om redundantie te verminderen en consistentie te verbeteren. Informatie over klanten, bestellingen en producten komt bijvoorbeeld in aparte tabellen terecht in plaats van één grote, platte lijst.
- Relaties worden cruciaal: Zodra we data in meerdere tabellen hebben verdeeld, moet we vastleggen hoe die tabellen aan elkaar gerelateerd zijn. Hoe koppelen we een bestelling aan de juiste klant? Hoe weten we welke producten bij een bestelling horen? Dit doen we via relaties (zoals de één-op-veel relatie tussen Klanten en Bestellingen via de KlantID).
- Complexe structuren zijn moeilijk mentaal te managen: Bij een kleine database met 2 of 3 tabellen kunnen we de structuur en de relaties misschien nog wel in ons hoofd onthouden. Maar zodra we tientallen of honderden tabellen hebben, met diverse relaties (één-op-één, één-op-veel, veel-op-veel), wordt het vrijwel onmogelijk om dit overzicht te behouden zonder visuele hulp.
- Een ERD is een Visuele Kaart: Een grafisch datamodel, zoals een ERD, biedt een visuele weergave van de hele database-structuur. Het toont de tabellen (entiteiten), de kolommen (attributen) en, cruciaal, de lijnen en symbolen die de relaties tussen de tabellen aangeven. Dit werkt als een wegenkaart voor onze database.
- Helpt bij het Ontwerp en de Communicatie: Tijdens het normalisatieproces helpt een ERD ons om na te denken over hoe we de tabellen moet opsplitsen en welke sleutels we nodig hebben om de relaties te leggen. Het is ook een onmisbaar communicatiemiddel binnen een team: programmeurs, database-beheerders en business analisten kunnen aan de hand van de ERD de database-structuur begrijpen en bespreken.
- Documentatie: De ERD dient als levende documentatie van hoe onze database is opgebouwd. Het is veel makkelijker om een diagram te lezen en te begrijpen dan een lijst met tabeldefinities en relatie-constraints.
Maak de databases solide met datanormalisatie en 3NF
Datanormalisatie, en in het bijzonder het streven naar de Derde Normaalvorm (3NF), is een fundamenteel concept voor iedereen die leert werken met databases. Het helpt ons gestructureerde, efficiënte en betrouwbare databases te ontwerpen die de ruggengraat vormen van robuuste software-applicaties.
Door de regels van 3NF toe te passen, minimaliseren we redundantie en beschermen we onze data tegen veelvoorkomende problemen bij het invoegen, bijwerken en verwijderen.
Datanormalisatie leidt kortom tot een gestructureerde database met meerdere, gerelateerde tabellen. Naarmate de omvang en complexiteit van de applicatie toenemen, neemt ook het aantal tabellen en de complexiteit van hun relaties toe. Een grafisch datamodel (ERD) wordt dan essentieel om dit complexe netwerk van tabellen en relaties visueel weer te geven, te begrijpen, te ontwerpen en te onderhouden. Zonder zo’n “wegenkaart” verdwalen we snel in de structuur van een genormaliseerde database van enige omvang. Pas deze principes toe bij in database-projecten en bouw op die manier een sterke fundering voor de toekomstige applicaties.
Mogelijk is dit een vertaling van Google Translate en kan fouten bevatten. Klik hier om mee te helpen met het verbeteren van vertalingen.
Laatste artikelen
- De mens als AI agent: van meester naar slaaf
- Exploratief testen: Agile softwaretesting zonder testscripts
- DRY Principe: Fundament voor Schone Code en Onderhoudbare IT
- Citizen Developer Governance: Veilige Low-Code/No-Code voor medewerkers en compliance
- Uninterruptible Power Supply (UPS): Noodstroomvoorziening voor IT-Infrastructuur
- De Cloud Security Baseline: 10 kritieke auditpunten voor AWS, Azure en GCP
- Model Drift: de onvermijdelijke veroudering van AI-modellen
- Digitale geletterdheid: de sleutel tot IT-projectsucces
- Soft skills IT: technisch inzicht en probleemoplossend vermogen
- Geautomatiseerd testen van software brengt snelheid en kwaliteit