DevOps Code – Exception Management
Gerelateerde artikelen
Exception Management Introduction

From an operating perspective, exception management is one of the most important function of an application or system software component. The way in which this is designed determines the ability to correct deviations in the functionality and quality of the objects to be controlled.
Exception Management Definitions
Event Catalogue
A event catalogue is a list of all events of an application including the identification and the category (information, warning or exception).
Event Management
This is an ITIL® process that defines which events are valuable to recognize and to capture. These may be information events such as starting or stopping a process. It is also possible that there is a probability of an exception. This is called a warning. An example is the 80% full disk. In case the application or infrastructure component does not function properly, there is an exception.
Exception
An exception is situation in which the normal flow of an application or system software component is disturbed.
Exception Management Concepts
Exception management
This is a process of determining potential disturbance, programming of the exception in the software, and monitoring of the exception in order to rectify the effect.
Incident management
The difference between an exception and an incident is that an exception is an event that may lead to an incident but in itself is not an incident. An incident is a possible deviation from the SLA. Many monitor tools offer the ability to create automatically an incident based on an exception. However, in some cases exception events are actually concerning the same incident. In that case the incident will be created and the causing exception events are linked to the incident.
Health model
A health model is a concept used to determine which error paths are possible prior to the realization of a theme, epic or feature. This is never exhaustive, but if 80% of the possible disturbances can be determined, that’s already a lot. During the lifecycle of the application, the health model can be further expanded.
In addition to the determination of possible disturbances, the health model analyses is used to look at what information is then available to establish if the unwanted event has occurred. And more importantly, whether that situation is still occurs at the moment. Finally, the health model indicates which monitor facility is capable of detecting this.
Exception Management Best Practices
In practice, the developer only looks whether or not the information system (application, system software and hardware) accomplished the happy path. Beforehand there is no or a little investigation for possible alternative paths and the error paths. An alternative path is a possible course of a transaction other than the happy path. However, the alternative path is not wrong. The error path, on the other hand, is incorrect. The error has to be taken into account. This article describes the exception management process within a DevOps perspective in order to improve the quality of the services for the customer.
Where does an exception occur?
It is very common that exception management is left to the developer. He/she will usually determine whether a different behaviour or exception can occur in the flow of its source code. Usually this is when leaving the context of the code like:
- Calling an internal or external application function
- Using an API function of a database management system
- Writing information to a storage medium based on a function
- Communicating with an infrastructure service (print service, e-mail service, LDAP service, etc.) based on a function.
The developer then programmes the retrieval of the return status at this function. If this is not ‘0’ then there must be an exception.
Which information needs operations?
Many programmers do not know what someone of operations needs to have to fix a disruption. Practical examples are of wrong error messages are:
- After a night batch of 400,000 transactions, there was an error in the application log file “Something went wrong”. Nobody knew what to do.
- In a national system with tens of millions of messages a year, the application appeared to give a java stacktrace dump on the console in the computer center in case of an error message. The developer assumed that he would be called during the disruption and that this information would then be passed on.
- An application writes four lines of text to an error log, while the monitor facility only takes into account one text line per exception. Three lines were always ignored.
- Error codes in the error message are not unique.
- The error message reads: “Something’s wrong, if this happens more often than you should contact the system administrator”.
- No error message but a system page display.
- No error message because no exception has been programmed.
- …
With DevOps, developers and operations are closer together, so they can learn from each other how to write better exceptions. The following information is very useful to take along in the Exception Management SRG:
- Each error message has a unique number
- The error message is dynamic. This means that the text is not recorded hard-coded in the software, but is retrieved from an exception file or exception database so that it
- Can be maintained
- Can be translated
- Extracted for the event catalog
- Meta data can be provided
- Error messages are sent not only to the console and / or the user’s screen, but also to a log file
- The error message is provided with the following configuration meta data (if applicable)
- The S-CI that made the exception (the application)
- The location in which that exception was written (function name and code)
- The S-CI or CI that was tried to communicate with
- The S-CI or CI on which the S-CI is hosted at the time of exception
- The error message is provided with the following run state meta data (if applicable)
- The date and time of the exception
- The key values of the business transaction concerned
- The User ID or System Account
- The error message is provided with the following resolution information
- The type: exception, warning, information
- The severity: 000-999, with each number indicating a situation like
- 000 = status information report
- 010 = connection error
- 011 = deadlock error
- 012 = authorisation error
- 999 = data curruption error
- The solver: user, functional administrator, application manager, infrastructure administrator
- The error message is provided with the error resolution:
- Restarting the system by …
- Restore backup by …
- Analyse unavailability of infrastructure service by …
Ad 1. Unique error message
Often only a generic number is provided. For continuous monitoring it is important that, in the development environment, a unit test will determine whether the error message is monitored and whether the correct information is written in the log. Every exception must be observed in the development environment. Therefore, a unique error situation is important. Furthermore, in the rest of the DTAP street, it is very important to determine quickly what’s wrong. Because of the uniqueness of the message, this is determined much quicker.
Ad 2. Dynamic message
Re-compiling a source code to adjust the error message is obviously a waste. The external capture also makes it possible to set the application multi-language. From many applications it is not known what can go wrong because the error messages do not meet the uniqueness criterion and are also hardcoded. Worse is if no exception is programmed at all.
Ad 3. Save error messages
If a user calls for an incident and mentions an error code, then it is very useful that this is also recorded in the logfile. This is because either the user does not call or does not know exactly what steps he / she has taken with the information system prior to the error message.
Ad 4. Configuration data
Configuration information is very important for the determination of the location of the error message, but also for problem management analyses. This seems a lot of work, but this can be programmed in a central exception handler and therefore costs very little extra time.
Ad 5. Run information
From Security perspective may not always all information is allowed to include in a logfile. But key values are often allowed. Certainly in transaction chains this is very useful information. The user’s ID is important for matching events in the monitor device with the incidents of the service desk.
Ad 6. Resolution information
Automatically routing events through the service management tool is an important profit by in reducing the downtime. Incorrect routing however, has a counter effect. Meta data in the exception reduces this opportunity of erroneous routing. The category is important information for the monitor facility to determine whether or not the event should be passed on as an incident to the service management tool.
The resolution information is the most useful information to prevent waste. The developer should think as an operations employee: “If this happens later, what should my colleague do to restore service again?” By doing this once, there is no need to look again for what happens in the run phase.
How to determine that the exceptions are complete?
For Operations, it is crucial that all events that are critical are monitored based on an exception in the software. However, the question is whether the event catalogue is complete. In the best case it is filled by the use an exception file or database. However this exception file only contains the errors that are programmed by the developer. A better way to be sure to be complete is to perform a risk analysis prior to the programming of the theme, epic or feature after it has been determined whether all possible errors have been captured.
The risk analysis can be performed using an Ishikawa model (see Figure 1-1). During this analyses the DevOps team looks at what might be the cause of an expected error path, in this case a non-complete set of files which is needed by the application. The cause is then searched in the main categories (Man, Machine, Measurement, Method and Material). Therein, subcategories are identified and, finally, the cause of the error.
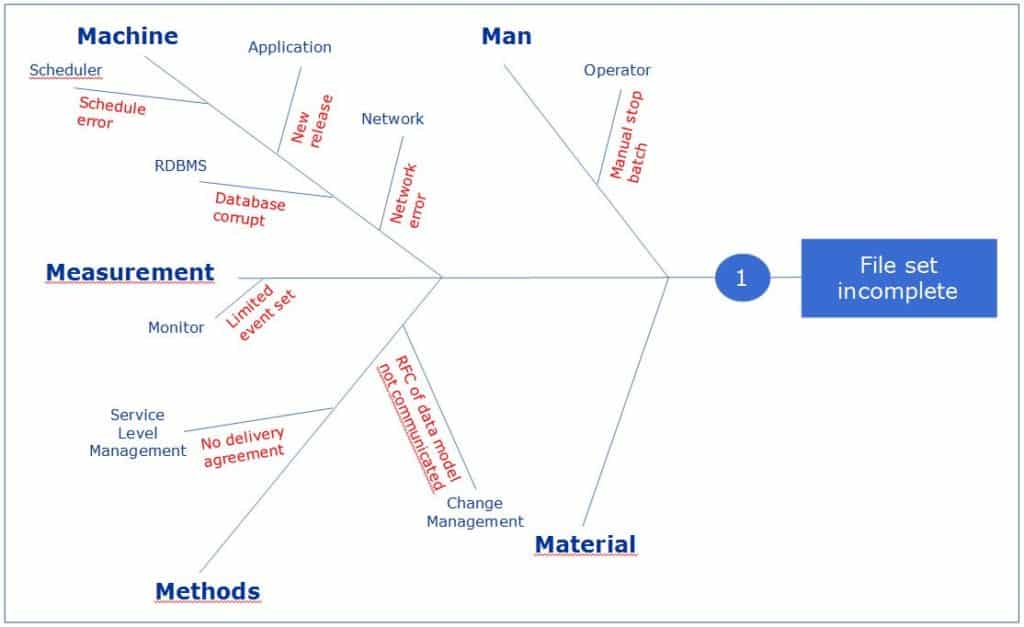
Then the health model is filled in for this situation. This is a spreadsheet with, for example, the following structure:
| Component | Event | Excep-tion Id | Exception | Foot print | Monitor function | Monitor tool | Resolution |
| Pre stage | 1 | 10001 | No delivery agreement | Crontab logfile | Component monitor | SPS Gensys | Send file |
| Dataware-house | 1 | 10002 | Database corrupt | SQL Errorlog | Component monitor | SPS Gensys | Restore database |
| Engine B | 1 | 10003 | Scheduler error | Scheduler errorlog | Component monitor | SPS Gensys | Reschedule job |
Table -1, Health model for event ‘File Set Incomplete’.
Based on the health model, the developer must ensure that the programming takes into account the exceptions. The test cases for the application should result in a minimum of three error paths.
Exception management in the DevOps process
In Table 1-2 the relationship between the exception process and the DevOps process is defined.
| Plan | For all themes and epics:
|
| Code | For each feature:
|
| Build |
|
| Test |
|
| Release |
|
| Deploy |
|
| Operate |
|
| Monitor |
|
Table -2, Health, Exception management in the DevOps process.
Conclusion
The time that is needed to resolve incident can be decreased enormously by exception management. The DevOps way of working makes it easy to accomplish this.

Discuss with us about this article on LinkedIn.
More information
Related Books:
DevOps Best Practices, ISBN: 9789492618078
Agile Service Management with Scrum, ISBN: 9789071501807
Related training sessions:
- DevOps Foundation
- DevOps in practice
- DevOps Master
- Masterclass DevOps Operations
- Masterclass DevOps Application Development
- Masterclass DevOps Architecture
Related Article:
Mogelijk is dit een vertaling van Google Translate en kan fouten bevatten. Klik hier om mee te helpen met het verbeteren van vertalingen.
Laatste artikelen
- De IT-offerte: Waar moet je op letten bij Software en SaaS?
- De ICT-checklist voor het moderne kantoorgebouw
- De paradox van Cloud FinOps Governance: kostenbeheersing in de cloud
- De mens als AI agent: van meester naar slaaf
- Exploratief testen: Agile softwaretesting zonder testscripts
- DRY Principe: Fundament voor Schone Code en Onderhoudbare IT
- Citizen Developer Governance: Veilige Low-Code/No-Code voor medewerkers en compliance
- Uninterruptible Power Supply (UPS): Noodstroomvoorziening voor IT-Infrastructuur
- De Cloud Security Baseline: 10 kritieke auditpunten voor AWS, Azure en GCP
- Model Drift: de onvermijdelijke veroudering van AI-modellen