
Veel organisaties worstelen met het inrichten van hun monitorvoorziening om de afgesproken servicenormen meetbaar te maken. Hoe kan de monitorvoorziening onder architectuur worden vormgegeven? En hoe kunnen aan de hand van deze aanpak tien veelvoorkomende problemen worden opgelost?
Dit artikel geeft aan hoe vanuit service management architectuur een kader gesteld kan worden aan het ontwerp en de inrichting van de monitorvoorziening om zo problemen tijdens het gebruik van de monitorvoorziening te voorkomen. Veel organisaties richten een monitorvoorziening in door een product te kopen en aan de slag te gaan. Vaak worden vóór de aanschaf van de voorziening requirements opgesteld en wordt een vergelijking gemaakt van een aantal tools.
Maar in de praktijk blijkt vaak dat de monitorvoorziening niet goed voorziet in de gewenste functionaliteit en de informatiebehoeften. Ook vormt het aantal monitortools in veel organisaties een onoverzichtelijk portfolio. Er wordt bij bezuinigingen naar hartenlust in gesneden, vaak zonder dat de consequenties bekend zijn. Dit artikel geeft aan de hand van een architectuur-stappenplan een oplossing voor een aantal veelvoorkomende monitorknelpunten. Het kader dat nodig is om de monitorproblemen op te lossen wordt beschreven in de eerste drie stappen van dit stappenplan (beleid, architectuurprincipes en architectuurmodellen).
Ondanks de tijd, geld en energie die gestoken wordt in het meetbaar maken van een ICT-service blijkt achteraf meer dan eens dat het beoogde resultaat niet is behaald. De volgende tien problemen zijn karakteristiek voor het falen van de monitorvoorziening:
De genoemde problemen vereisen structurele tegenmaatregelen die hoog in de organisatie geborgd moeten worden. Een effectief middel is om afspraken te maken op managementniveau door beleidspunten op te nemen in het ICT-beleid en dit beleid te vertalen naar architectuur-principes en architectuurmodellen. Dit kader moet door (service-)architecten bewaakt worden in zowel de lijn- als de projectorganisatie.
Naast deze strategische verankering is het belangrijk om de inrichting van de monitorvoorziening ook op tactisch niveau te borgen in het service level management proces en operationeel in een monitorproces. Deze top-downbenadering is in Figuur 1 uiteengezet. Links is de indeling richten, inrichten en verrichten te zien. Van boven naar beneden zijn de stappen beeld, macht, organisatie en resources weergegeven. Deze stappen zijn gelijk aan die van het paradigma van de verandermanager. Dit paradigma geeft aan dat deze vier stappen van boven naar beneden moeten worden doorlopen. Bij een conflict moet de oplossing twee niveaus hoger worden gezocht.
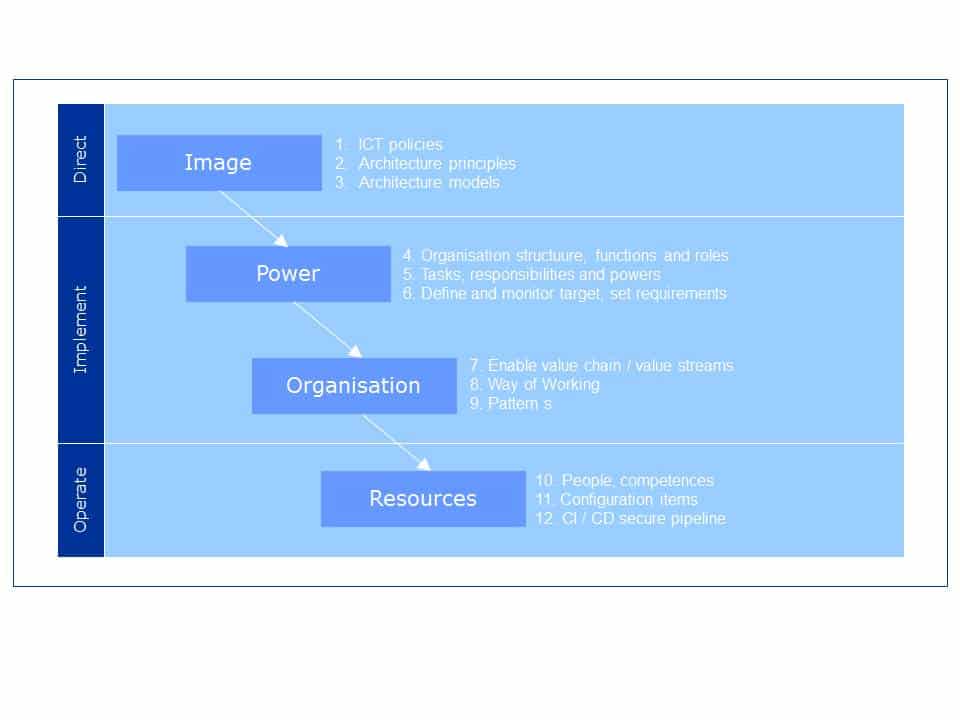
Figuur 1, Service Management Architectuur-model (SMA).
De stap beeld is het domein van de (service-)architecten. Deze functionarissen geven richting aan de monitorvoorziening door het ICT-beleid te vertalen naar architectuurprincipes en architectuurmodellen en deze vervolgens te borgen tijdens de inrichting van de monitorvoorziening en uitvoering van het monitorproces. In dit artikel gaat het alleen om de stap beeld, omdat dit de oplossingsrichting omvat voor de genoemde problemen. Wel wordt een aantal voorbeelden gegeven van hoe de aangegeven richting in de stappen macht, organisatie en resources tot uitdrukking kunnen worden gebracht.
Het goed inregelen van een complete monitorvoorziening in een middelgrote tot grote organisatie blijkt in de praktijk meer dan eens een meerjarenplan te zijn. Helaas wordt gedurende die doorlooptijd nogal eens letterlijk en figuurlijk de stekker uit de voorziening getrokken vanwege bezuinigingen en uitblijvende resultaten. Daarom is het van belang dat de monitorvoorziening geborgd is in zowel ICT-beleid als in de architectuur. In het ICT-beleid kunnen monitoraspecten opgenomen worden als monitorvolwassenheid, monitorportfolio, sourcing en partnership.
Het belangrijkste beleidsuitgangspunt is de volwassenheid van de monitorvoorziening. Dit bepaalt het ambitieniveau van deze voorziening in de gehele organisatie. Meestal worden een aantal volwassenheidsstadia onderkend.
Het volwassenheidsniveau van de monitorvoorziening moet zorgvuldig worden gekozen. Deze keuze staat namelijk niet op zich. Zo vereist het monitoren van core value streams dat de gebruikersorganisatie deze value streams onderkend heeft en de behoefte heeft om de doelstellingen van de geautomatiseerde ondersteuning van deze value streams te meten en op de meetresultaten te sturen. Ook moet de serviceorganisatie een monitorvoorziening op core value stream kunnen inrichten en configureren, zoals het meten van businesstransacties en het kunnen waarnemen van trends.
Eenmaal in productie genomen moet de serviceorganisatie samen met de business de meetresultaten kunnen interpreteren om verbeteringen aan te brengen in de serviceorganisatie en / of in de gebruikersorganisatie indien de doelstellingen van de core value streams niet worden gehaald. Hierbij geldt de randvoorwaarde van een business-alignment met de serviceorganisatie. Een onvolwassen serviceorganisatie die alleen product georiënteerd werkt zal immers niet in staat zijn om de servicenormen te monitoren die een meer volwassen gebruikersorganisatie stelt. De serviceorganisatie moet in dit geval in volwassenheidsniveau groeien om de business-alignment goed vorm te geven.
Ook komt het voor dat de serviceorganisatie volwassener is dan de gebruikersorganisatie. Dit kan leiden tot een spagaat waarbij de serviceafspraken op een lager volwassenheidsniveau worden gemaakt dan het niveau waarop de serviceorganisatie acteert. De rechtvaardiging van de extra kosten voor de monitorvoorziening is dan om aan te tonen dat de serviceorganisatie in ieder geval in control is (bijvoorbeeld vanwege wettelijke verplichtingen). Het moeilijkste van de monitorvolwassenheid is het gekozen ICT-beleid te effectueren. Vaak ontbreekt het aan architectuur-control en managementmandaat om het ICT-beleid te vertalen naar kaders en hieraan vast te houden. Een zwalkend beleid is het gevolg, net als geldverlies en frustratie op de werkvloer.
Met de komst van het Agile werken en het vormen van DevOps teams wordt de service-organisatie opgedeeld in onafhankelijk werkenden teams. In de praktijk blijkt dat er vaak vanzelf een gelaagde monitorarchitectuur ontstaat. Elke laag heeft een andere vrijheidsvorm. De bovenste laag bevat de verplicht te gebruiken tools door een DevOps team. De toepassing van die monitortools is verplicht vanwege het feit dat er ketens moeten worden gemonitord waarbij meer DevOps teams betrokken zijn.
De onderste laag is vrij in te vullen en de tussenlaag is bedoeld om binnen bepaalde kaders een eigen configuratie van de monitorvoorziening te treffen. Het monitortoolportfolio daarna opgedeeld over de drie lagen. Door deze gelaagde toolarchitec-tuur is het mogelijk om aan de ene kant de economics of scales te behouden en een keten goed in control te houden. Aan de andere kant biedt deze toolarchitectuur de vrijheid aan de DevOps teams om zelf een goede invulling te geven aan de mate van vereiste control.
Veel organisaties zien door de bomen het bos niet meer als het gaat om monitortools. Om dit probleem het hoofd te bieden, wordt vaak gekozen voor een single vendor-beleid. Dit houdt in dat voor nieuwe tools één vaste leverancier wordt gekozen. De bestaande tools worden langzaam uitgefaseerd. Zo is een betere toolintegratie te bereiken. In de praktijk blijken altijd wel uitzonderingen op dit beleid nodig te zijn. Daarom is het belangrijk dat in de keuze van de vendor en de monitoroplossing aspecten als open architectuur en integratiemogelijkheden hoog scoren.
Ook de sourcing is een ICT-beleidspunt waard. Zo worden steeds meer monitorservices als een SaaS (software as a service) aangeboden. Het opnemen als ICT-beleidspunt is belangrijk, omdat in geval van nieuwe monitorbehoeften eerst gekeken moet worden of de gewenste functionaliteit als SaaS beschikbaar is in de markt. Hierdoor is het niet nodig om tooling aan te schaffen en hoeven kennis en kunde voor de nieuwe tool slechts ten dele te worden opgebouwd. Afhankelijk van de grootte van de organisatie is het verstandig om een partnership met een monitortool-leverancier aan te gaan. Zo kunnen beide organisaties van elkaar leren. Het beleid kan dan worden afgestemd op de toekomstige mogelijkheden die een leverancier biedt.
Waar het ICT-beleid belangrijke beslissingen omvat, stippelt architectuur een migratiepad uit om vanuit de bestaande situatie (IST) te komen tot de gewenste situatie (SOLL). Hierbij worden architectuurprincipes en –modellen opgesteld ter kader en beeldvorming. Een principe wordt gedefinieerd door een oneliner die de gewenste richting geeft, de rationale die aangeeft wat bereikt moet worden, de implicatie die de gevolgen van het principe duidt en tot slot het risico dat beheerst moet worden. Ook is het belangrijk om de betrokken service management architectuur stappen aan te geven (stappen 4 t/m 12 uit Figuur 1), omdat hiermee geduid wordt welke architectuurcontrol het principe vereist.
In Tabel 1 is een voorbeeld van een architectuurprincipe opgenomen dat een oplossingsrichting geeft voor het eerste van de tien genoemde probleem. Het principe schrijft niet de oplossing voor in de vorm van een ontwerpeis, maar alleen het kader waarbinnen de oplossing gezocht moet worden. Dit is het fundamentele verschil met een requirement. Het benoemde risico weerspiegelt hier probleem 1.
| P# | PR-Mon-01 |
| Principe | Verstoringen die door E2E-metingen zijn waargenomen worden verklaard door componentmetingen. |
| Rationale | Niet alle verstoringen worden waargenomen door E2E-monitoring, in ieder geval niet de verstoringen aan dubbel uitgevoerde infrastructuur- en/of applicatiecomponenten. Dit kan leiden tot grote verstoringen die voorkomen hadden kunnen worden. Tevens geeft de E2E-monitoring niet de exacte locatie weer. Componentmonitoring geeft wel invulling aan deze eisen, maar het is moeilijk om alle componenten van een ICT-service compleet te monitoren. Een combinatie van E2E-monitoring en componentmonitoring lost veel van deze problemen op. |
| Implicatie | Elk onderliggend infrastructuur- of applicatiecomponent waarvan de ICT-service gebruik maakt moet gemonitord worden voor alle van toepassing zijnde kwaliteitsaspecten zoals beschikbaarheid, performance, capaciteit en beveiliging. |
Tabel 1, Dekkingsgraad architectuur-principe.
Dit principe moet worden uitgewerkt in een aantal requirements waarin deze correlatie van E2E- en componentmonitoring is uitgewerkt (SMA stap 6). Een voorbeeld is het vereisen van het hanteren van de Component Failure Impact Analyse (CFIA) van IBM, zoals ITIL die aanbeveelt, voor het bepalen van de bij een ICT-service betrokken componenten. Een andere requirement is dat in de SLA-rapportage vermeld wordt welke gebreken aan de monitorvoorziening zijn aangetroffen en hoe deze opgelost worden. Hierbij is de monitorcontrolematrix zoals in Tabel 2 een handig hulpmiddel.
| Monitor Controle Matrix | Componentgebaseerde metingen | ||
| Binnen normen | Buiten normen | ||
| E2E-metingen XE E2E meting | Binnen normen | De servicenormen XE “service:- norm” zijn gehaald. | Bepaal of en hoe de E2E-monitor-functionaliteit aangepast moet worden. |
| Buiten normen | Bepaal of en hoe de component-gebaseerde monitorfunctionaliteit kan worden aangepast. | Bepaal welke infrastructuur- of applicatiegebreken ten grondslag liggen aan deze verstoringen XE “verstoring”. | |
Tabel 2, Monitorcontrole matrix.
Met het principe PR-Mon-01 is probleem 1 goed te voorkomen of te beheersen. Het is belangrijk te onderkennen dat er aan een probleemstelling verschillende oorzaken ten grondslag kunnen liggen. In dat geval zijn er wellicht ook verschillende architectuurprincipes nodig. Hierbij moet worden voorkomen dat er te veel architectuurprincipes worden opgesteld. Ook moeten architectuurprincipes kaderstellend zijn en niet voorschrijvend, anders verworden de principes tot requirements.
In Tabel 3 zijn een aantal monitorprincipes opgenomen met de duiding welk probleem opgelost wordt met welk principe.
| PR# (P#) | Principe |
| PR-Mon-01 (P1) | Verstoringen die door E2E-metingen zijn waargenomen worden verklaard door componentmetingen. |
| PR-Mon-02 (P2) | Van elke ICT-service zijn de onderliggende infrastructuur- en applicatiecomponenten bekend. |
| PR-Mon-03 (P3) | Servicenormen in een SLA worden afgesproken in businesstermen. |
| PR-Mon-04 (P3) | Het niveau van ICT-serviceafspraken bepaalt het niveau en de functionaliteit van de monitorvoorziening. |
| PR-Mon-05 (P4) | De levenscyclus van de monitorvoorziening van de ICT-service is een integraal onderdeel van de levenscyclus van de ICT-service. |
| PR-Mon-06 (P5) | Alle events moeten worden geëvalueerd. |
| PR-Mon-07 (P6) | Elke monitortool wordt gemonitord op een juiste werking. |
| PR-Mon-08 (P8) | De meetpunten van de monitortools worden bepaald door de kritieke succesfactoren van de beheerprocessen en de bedrijfsprocessen. |
Tabel 3, Monitorprincipes.
Om te voorkomen dat in geval van een verstoring aan een component niet bekend is welke ICT-service is geraakt, kan het PR-Mon-02 principe worden gehanteerd. Hierdoor is het mogelijk om de oplostijd van verstoringen aan infrastructuur- en applicatie-componenten te baseren op het belang van de business. Er zijn diverse requirements nodig om dit principe te borgen (SMA stap 6). Zo moet de relatie tussen een ICT-service en de betrokken CI’s in de configuratie-managementdatabase (CDMB)-tool geadministreerd kunnen worden, net als eventuele relaties tussen ICT-services onderling. Daarnaast moet het monitorprocesontwerp de vereiste rapportages beschrijven (SMA stap 7). Dit principe heeft ook grote gevolgen voor de keuze van de CMDB-tool (SMA stap 11).
Het gevaar van het monitoren van een ICT-service is dat deze niet aansluit op de service-afspraken. Dat een server beschikbaar is, wil nog niet zeggen dat een gebruiker van een ERP-applicatie die op die server draait kan werken.
Zelfs als in de SLA alleen een beschikbaarheid op serverniveau is afgesproken, wil dit niet zeggen dat de gebruiker ook tevreden is. Twee principes die dit borgen zijn PR-Mon-03 en PR-Mon-04. Natuurlijk kan het voorkomen dat er een technische service is en dat de klant een technische SLA wil, zoals de beschikbaarheid van het WAN. Het principe PR-Mon-P3 voldoet dan nog steeds. De businesstermen zijn in dat geval alleen technisch van aard, maar zijn wel de termen die de klant zelf hanteert. Het principe PR-Mon-04 geldt ook nog steeds. De meting moet namelijk plaatsvinden op WAN-niveau en niet op routerniveau.
Vaak wordt vergeten dat een robot die een applicatie E2E meet gevoelig is voor aanpassingen aan de applicatie. De kleinste verandering aan de gebruikersinterface van de applicatie kan het robotscript onbruikbaar maken. De robotfunctionaliteit moet als onderdeel van de applicatie worden gezien. Een bruikbaar principe is in dit geval PR-Mon-05. Dit principe impliceert dat de organisatie die verantwoordelijk is voor het functioneel beheer van de ICT-service ook het beheer van de monitorvoorziening voor zijn rekening neemt. Normaliter is dit de gebruikers-organisatie, want daar is de functionele kennis aanwezig om te bepalen welke aspecten van een ICT-service gemonitord moeten worden. De business moet dan ook van meet af aan betrokken zijn bij de opzet van de monitorfunctie.
Veel organisaties zijn niet in staat om de events die door de monitorvoorziening worden waargenomen te verwerken en draaien de filters zo ver dicht dat alleen die events waarvan ze een alert willen ontvangen actief worden bewaakt. Dit leidt tot prachtige maar onbetrouwbare rapportages. In plaats van aan dit kraan-dichtprincipe moet er juist gewerkt worden aan een kraan-openprincipe PR-Mon-06. De events die onderkend zijn als schadelijk worden als incident aangemeld bij de servicedesk (negatief filter). De events die onderkend zijn als vertrouwd worden genegeerd (positief filter). Van events die alleen in bepaalde hoeveelheden schadelijk zijn, wordt op basis van een threshold een alert afgegeven (statistisch filter). Het residu aan events moet dagelijks worden geëvalueerd en opgenomen in een van de drie filters. Hierdoor zal het residu steeds verder slinken tot een behapbaar aantal.
Het gevaar van het kraan-dichtprincipe is dat het lang kan duren voordat geconstateerd wordt dat de monitorvoorziening überhaupt niet aan staat en/of verkeerd geconfigureerd is.
Een principe dat dit voorkomt is PR-Mon-07. Dit kan bijvoorbeeld worden ingevuld aan de hand van een E2E-monitoring.
De bestuurlijke behoeften van zowel de gebruikersorganisatie als de serviceorganisatie vormen de basis voor de definitie van de ICT-services monitoring en de toegekende normen Dit impliceert het principe: PR-Mon-08.
Architectuurmodellen zijn een uitstekend middel om de gewenste monitorvoorziening (SOLL) te schetsen. Door ook een model op te stellen van de huidige monitorvoorziening (IST) kan een duidelijk migratiepad van IST naar SOLL worden uitgestippeld. Figuren 2 en 3 tonen een voorbeeld van zo’n IST/SOLL-monitorarchitectuur-model.
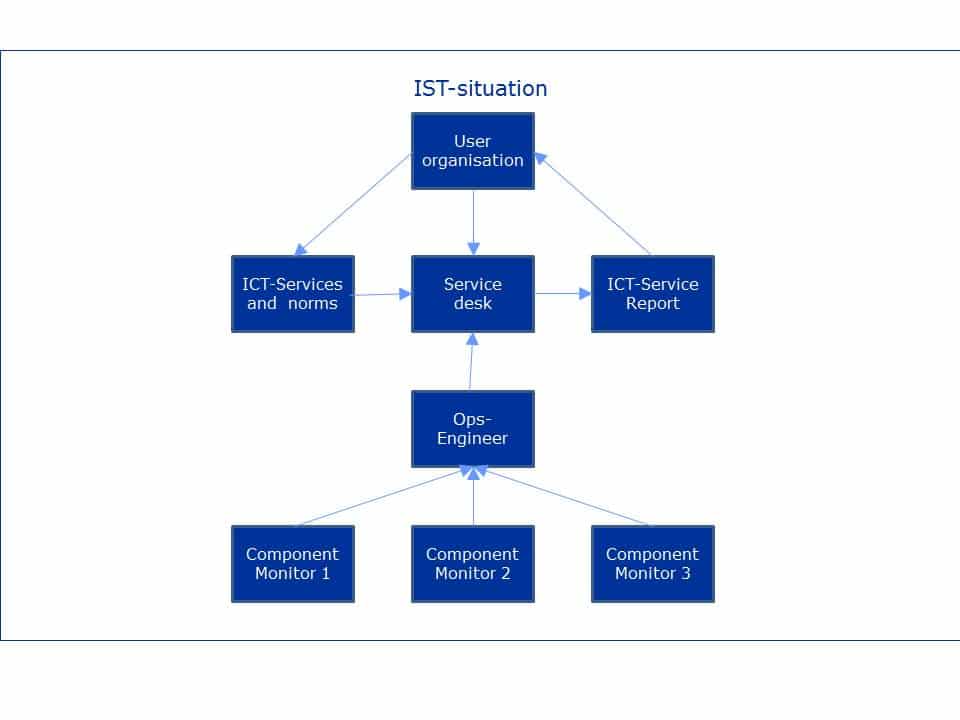
Figuur 2, IST Monitorarchitectuur-model.
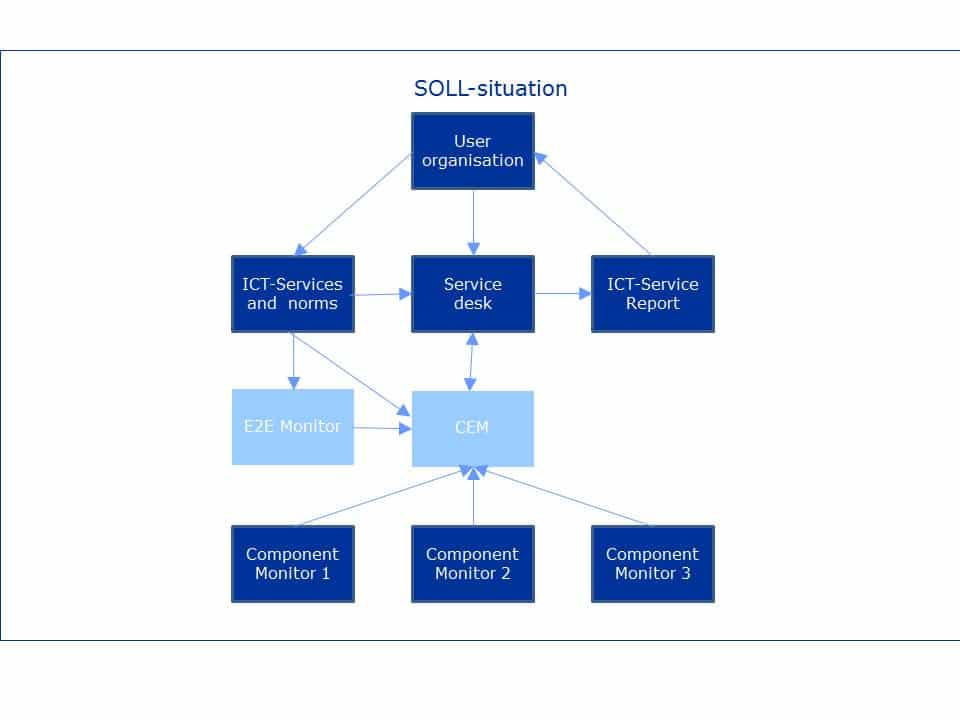
Figuur 3, SOLL Monitorarchitectuur-model.
In de huidige situatie is er een duidelijk onderscheid tussen servicemanagement en systeem-management. Vanuit servicemanagement zijn de ICT-servicenormen onderkend. Deze dienen als maatstaf voor de ICT-service, die bewaakt worden op basis van de meldingen die bij de servicedesk binnenkomen. Dit is tevens de basis voor de rapportages.
De component-monitortools geven events af die de systeembeheerder interpreteert. Als een Ops-engineer het nodig acht, maakt hij handmatig een incident aan in de servicedesk-tool. Het moge duidelijk zijn dat in deze IST-situatie vele van de tien genoemde problemen zich kunnen voordoen. Om deze problemen op te lossen, biedt de in Figuur 13‑12 geschetst SOLL- situatie soelaas.
Net als in de huidige situatie stelt de servicelevelmanager in samenwerking met de gebruikers-organisatie de normen voor de ICT-services vast (PR-Mon-03). Deze normen dienen als maatstaf voor de servicedesk medewerkers, de E2E-monitor (PR-Mon-04) en de Centrale Event Manager (CEM). De CEM krijgt events binnen van de E2E-monitor en de componentmonitortools. In de CEM is de ICT-service gemodelleerd op basis van de onderliggende infrastructuur- en applicatie componenten (PR-Mon-02). Hierdoor kunnen verstoringen die E2E worden gemeten verklaard worden door componentmetingen (PR-Mon-01). Op basis van business rules leidt een event wel of niet tot een registratie van een incident in de servicedesk. Op basis van de ingestelde servicenormen vindt de bewaking plaats in de servicedesk en wordt er een SLA-rapportage aangemaakt. Dit architectuurmodel verschilt per organisatie en kan vaak nog verder gedetailleerd worden. De detaillering moet beperkt blijven tot een kaderstelling en geen ontwerp worden.
De Ops-engineer is in de SOLL-situatie zeker niet overbodig geworden. Zijn inzet is nu echter gericht op het uitbouwen en verbeteren van de monitorvoorziening in plaats van als monitortool te fungeren. Hij is nu in de gelegenheid de kwaliteit van de serviceverlening te verhogen en zorg te dragen voor business-alignment.
Het verschil tussen de IST- en de SOLL-situatie is duidelijk te zien. De monitortools hebben in de bestaande situatie geen geautomatiseerde interface met de servicedesktool.
Ook is nog niet voorzien in een E2E-monitorvoorziening. Het migratiepad om van IST naar SOLL te komen kan bijvoorbeeld bestaan uit de volgende ‘volwassenheidsstadia’:
1. Componentmonitoring
2. E2E-monitoring
3. Correlatie component- en E2E-monitoring
4. Bedrijfsprocesmonitoring.
Monitorclassificatiemodel
Een andere vorm van een monitorarchitectuur-model is een classificatiemodel voor monitortools. Ook dit is een handig gereedschap om de gewenste beeldvorming te bereiken.
Het inregelen van een goede monitorvoorziening vereist niet alleen een borging op operationeel en tactisch niveau. Juist op strategisch niveau dient een anker aanwezig te zijn om de inrichting van de monitorvoorziening te borgen. Het anker wordt gevormd door het vastleggen van de te varen koers aan de hand van beleidsuitgangspunten. Dit beleid dient voorzien te worden van een architectuurplan waarin de huidige en gewenste situatie inclusief migratiepad worden vastgelegd. Architectuurprincipes en -modellen zijn de instrumenten voor de (service-)architect om de uitgestippelde koers te borgen.
Continuous Monitoring, ISBN:978 94 92618 498
Beheren onder architectuur, ISBN:9789081338011
Masterclass Continuous Monitoring ITMG.

Mogelijk is dit een vertaling van Google Translate en kan fouten bevatten. Klik hier om mee te helpen met het verbeteren van vertalingen.