Web 3.0 Semantisch web
Gerelateerde artikelen

Web 3.0
Web 3.0 geeft betekenis aan documenten en links. Het huidige web is te beschouwen als een verzameling documenten die via links met elkaar verbonden zijn. De werking van het web staat of valt door goede afspraken over de vorm (syntax) van webpagina’s en links. De inhoud (semantiek) van die documenten is voor webapplicaties onduidelijk. Het Web 3.0 zou een stap verder kunnen maken van het Web 2.0 door ook de inhoud van die documenten te begrijpen. Inhoud in termen van “entiteiten” zoals personen, locaties, telefoonnummers en “relaties” tussen die entiteiten, zoals persoon X “heeft” telefoonnummer Y en “woont op” adres Z.
Waarom is die betekenis belangrijk? Om met een klein voorbeeld voor iPhone bezitters te beginnen. De browser herkent daar een telefoonnummer in een webpagina. Een ‘click’ op dat telefoonnummer laat de iPhone bellen naar dat nummer. Met de ontwikkeling van mashups in het achterhoofd is de stap van ‘adres’ naar ligging op de kaart niet zo ver weg.
De Web 3.0 Zoekmachine
Naast het gebruik door deze webapplicaties, is het begrijpen van de inhoud van groot belang voor de kwaliteit van het zoeken op het web. Zoekmachines zijn momenteel vrij dom. Google doorzoekt miljarden pagina’s van het internet met de opgegeven zoekwoorden. De zoekmachine laat een lijst met pagina’s waarin die zoekwoorden voorkomen die qua vorm het meeste overeenkomen (“hert’” en ”bert”), met de betekenis houdt Google geen rekening (“hert” en “ree”).
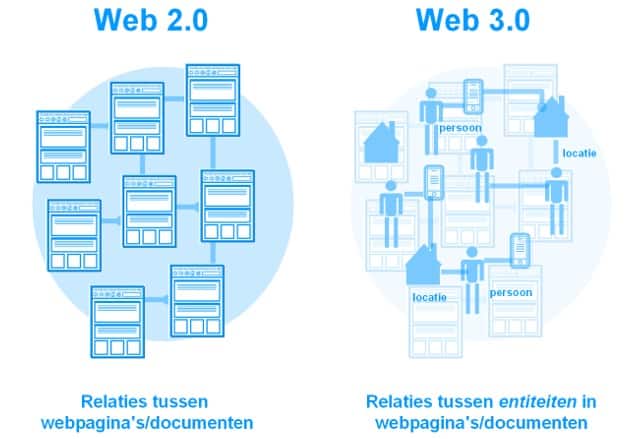
De kwaliteit van zoekmachines en andere webapplicaties kan dus sterk verbeterd worden door min-of-meer automatisch betekenis te geven aan entiteiten in webdocumenten. Maar dat is nog niet zo eenvoudig. De voortgang van Taaltechnologie en Artifical Intelligence is nog niet zover dat we de inhoud van documenten kunnen begrijpen. Deze top-down benadering (onder aanvoering van onder andere Alex Iskold) zal zeker niet binnen nu en tien jaar tot praktisch bruikbare resultaten leiden.
Web 3.0 en XML
En praktischer maar eveneens lastig te realiseren oplossing is de bottom-up benadering. Simpel gezegd pleit deze benadering ervoor om alle documenten op internet van extra informatie te voorzien zodat ze daardoor te beter te begrijpen zijn voor webapplicaties. Die extra meta-informatie (”annotaties”) beschrijft entiteiten in webpagina’s en hun relaties. Annotaties kunnen gebeuren in de vorm van RDF of Microformats. Het is de vraag of deze toch vrij onpraktische benadering in zijn algemeenheid tot succes zal leiden.
Veel kansrijker lijkt een benadering waarin via XML-standaards specifieke gebieden afgedekt worden, waar een duidelijk samenwerkings- of uitwisselingsbelang ligt. Voorbeeld is de financiële wereld waarin de XBRL stan-daard snel terrein wint (zie video onderaan de pagina). Voor sociale applicaties wordt bijvoorbeeld gewerkt aan APML (Attention Profile Markup Language) waarmee profielen van gebruikers en persoonlijke voorkeuren kunnen worden vastgelegd. Webapplicaties kunnen dat bestand lezen en de gebruiker vervolgens van gefilterde informatie voorzien. Een nog grotere hoeveelheid profielinformatie zal echter buiten de controle van de gebruiker vallen. Op dit moment wordt door internetreuzen als Google, Amazon en Yahoo ook al het klik- en zoekgedrag van gebruikers vastgelegd. Deze semantische gebruikersprofielen zijn momenteel al vele malen krachtiger dan deze bedrijven zelf willen toegeven.
Het oorspronkelijke artikel stond op 123management.nl.
Deloitte heeft uitstekend werk geleverd door de drie lagen van IT-infrastructuur samen te vatten en Web 3.0 te vergelijken met zijn voorgangers in de onderstaande afbeelding.

Lees ook meer over Web 1.0, Web 2.0 en Web 4.0.

Discussieer mee op LinkedIn.
Mogelijk is dit een vertaling van Google Translate en kan fouten bevatten. Klik hier om mee te helpen met het verbeteren van vertalingen.
Laatste artikelen
- De IT-offerte: Waar moet je op letten bij Software en SaaS?
- De ICT-checklist voor het moderne kantoorgebouw
- De paradox van Cloud FinOps Governance: kostenbeheersing in de cloud
- De mens als AI agent: van meester naar slaaf
- Exploratief testen: Agile softwaretesting zonder testscripts
- DRY Principe: Fundament voor Schone Code en Onderhoudbare IT
- Citizen Developer Governance: Veilige Low-Code/No-Code voor medewerkers en compliance
- Uninterruptible Power Supply (UPS): Noodstroomvoorziening voor IT-Infrastructuur
- De Cloud Security Baseline: 10 kritieke auditpunten voor AWS, Azure en GCP
- Model Drift: de onvermijdelijke veroudering van AI-modellen